
When Fable 5’s Premium Pays Off – And When It Doesn’t
By Carlo Martinez, Forward Deployed Engineer
When a model as powerful as Anthropic’s Claude Fable 5 drops, many engineering teams’ instinct is to immediately run it on their most complex projects. But at a certain point, the executive team will look past the AI hype and straight at the bottom line.
New models aren’t without risk. Security and reliability concerns remain as new tools are pressure tested by broad user groups. In the case of Fable 5, they can also come at a premium cost. For some projects, that premium is earned in efficiencies gained and quality of output compared to lower models. Other times, it’s not.
Fable 5 costs a flat 2x more than Claude Opus 4.8 and 3.3x more than Claude Sonnet 4.6 across token buckets. You’re not necessarily paying for better reasoning. In a long agentic loop, most of the bill goes toward cache reads (context re-reads), rather than the output that would justify the cost.
True ROAI™ (Return on AI Investment) is about optimizing token economics so you pay for the highest-value reasoning, not system churn. As my colleague Jason Symons argued in a recent article, model selection by workload is the most valuable – and most challenging – consideration in the ROAI equation.
To figure out exactly where Fable 5 earns its premium, we put the model through three highly demanding and deliberately different prompts. Each one was scored on cost, time, and output quality. Then, we compared the Fable 5 results against those of Opus 4.8 and Sonnet 4.6.
The bottom line: Fable 5 could be the right choice for some workloads and the wrong choice for others, but most enterprises have no way of telling the difference before the bill arrives.
Here’s what we learned.
Experiment 1: The Short, Dense Build
We gave Fable 5 a highly ambiguous, single-shot prompt: Create a website featuring a mechanical clock that actually works.
The output: A fully rendered 3D mechanical watch with an exploding view, accurate component placement, and an audible ticking sound. Check it out here.
Time: 6 minutes and 20 seconds.
Quality score: 9.4/10. There were a few minor cosmetic nits, the kinds of things a watchmaker would notice. Otherwise, the code was well-structured, and the output was correct on the first try without any modifications or debugging needed. Fable also reasoned to supply an accurate beat rate, quantized seconds sweep, and tooth-pitch geometry without explicit prompting. This is the kind of output a talented designer would spend a week producing.
Cost breakdown: $5.90. 58% of the bill went directly to the final deliverable, and just 9% went to cache reads. This is the healthy cost profile: you are paying for the output you wanted.
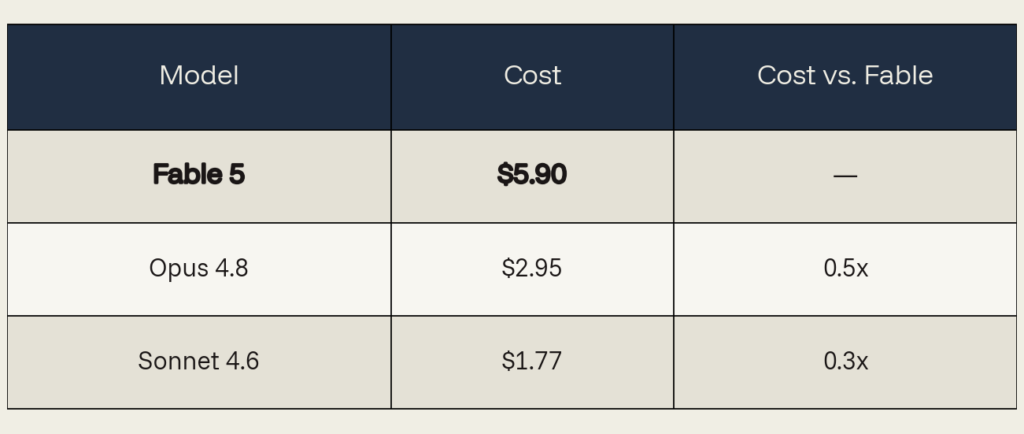
We measured Fable 5’s actual cost on each task. The Opus 4.8 and Sonnet 4.6 figures show what the same token usage would cost at their per-token rates. As the counterfactuals explain, those models would likely use a different number of tokens; more steps, more steering, or in some cases failing the task outright. Their real-world cost could be higher than the table suggests, or the task wouldn’t complete at all.
Counterfactuals: While lower-tier models may cost marginally less, they couldn’t match the quality of output. Opus 4.8 would have required multiple steps to reach this output, pushing total cost above Fable 5. Sonnet 4.6 wouldn’t have produced it in one shot at all.
Verdict: premium earned. This workload was visually intricate, required deep simulation reasoning, and benefited enormously from one-shot generation. Cheaper models would have either taken longer (driving cost back up) or failed entirely.
Experiment 2: The Data-Driven Investigation
We wanted to see if Fable 5 could handle data-driven chaos mathematics without being easily steered in the wrong direction. The prompt asked it to run a simulation investigating whether lunar gravity correlates with Powerball lottery numbers.
The output: The deliverable was a reproducible statistical study in six Python files (~578 LOC), two research documents, the real datasets, and a results PNG. Fable 5 identified the relevant formulas, built a working digital twin of the Powerball machine, and arrived at the expected result (a correlation statistically indistinguishable from zero) without being led astray.
Time: 91 minutes.
Quality score: 9.7/10. Interleaving data downloads from thousands of lottery draws and years of NOAA tide data, Fable 5 acted like an intellectually honest scientist. It didn’t torture the data to find a fake pattern, it correctly rejected the hypothesis that lunar placement causes lottery wins using rigorous Benjamini–Hochberg adjustments. To prove its code instrument wasn’t just broken, it set up positive controls, proving that while the lottery was unaffected by the moon, the same code accurately lit up the tidal patterns of the oceans. Fable 5 performed a fully reproducible, rigorous scientific study. There were a few coding imperfections, but they didn’t impact the validity of the result.
Cost breakdown: $14.80. Output remains the single largest bucket of the cost at 44%, but cache reads are slightly high at 29%.
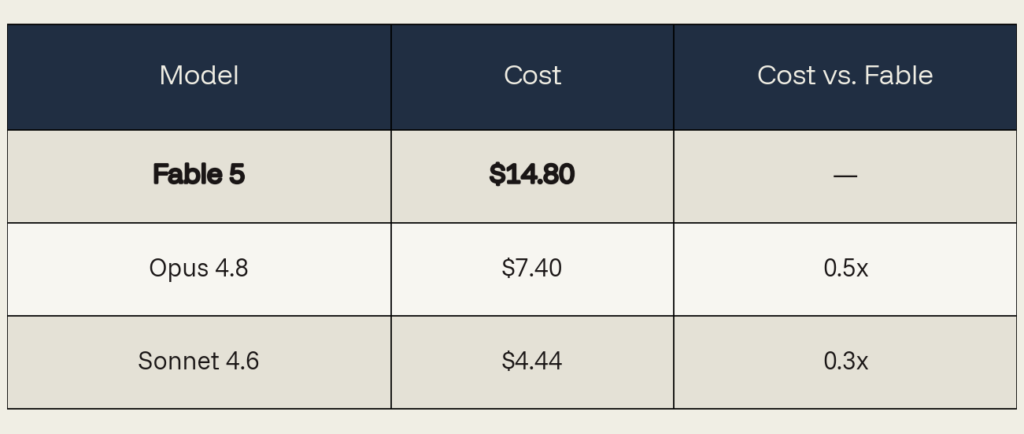
Same token usage, repriced.
Counterfactuals: Sonnet 4.6 would have needed us to plug in the formulas, point to the datasets, and supervise each step. Opus 4.8 would have understood the math, but still required steering – and tended to chase whatever direction we suggested, even when it was wrong. Fable 5 didn’t. When we tried to lead it astray, it corrected course.
Verdict: premium earned. This experiment had the strongest substantive case for paying the Fable 5 premium across our three studies. The dollar premium over Opus 4.8 was real but small. The supervision you didn’t have to do is the value that doesn’t show up on the invoice. When you can’t cheaply check the answer is correct, you pay for the model less likely to be wrong.
Experiment 3: The Delta Study
We pointed Fable 5 at a real, production-grade engineering task: a long agentic session improving a real local codebase.
The output: Fable 5 built a three-layer automation subsystem, trimmed away a massive amount of bloated scaffolding, fixed silent write errors, and passed all local linters cleanly. It produced ~1,284 lines of Python and shell and ~10 prose/config files across 274 assistant turns and 160 user turns.
Time: 76 minutes.
Quality score: The quality was high. The output held up under independent re-execution. This is real, working, well-built output – the kind of work that can justify a premium model if the premium bought the quality. In this case, it didn’t.
Cost breakdown: $111, but output was only 16% of the bill. Cache reads across those 274 turns made up 52% of the token cost. That is a structural cost that scales with turns and context size, not with model tier.
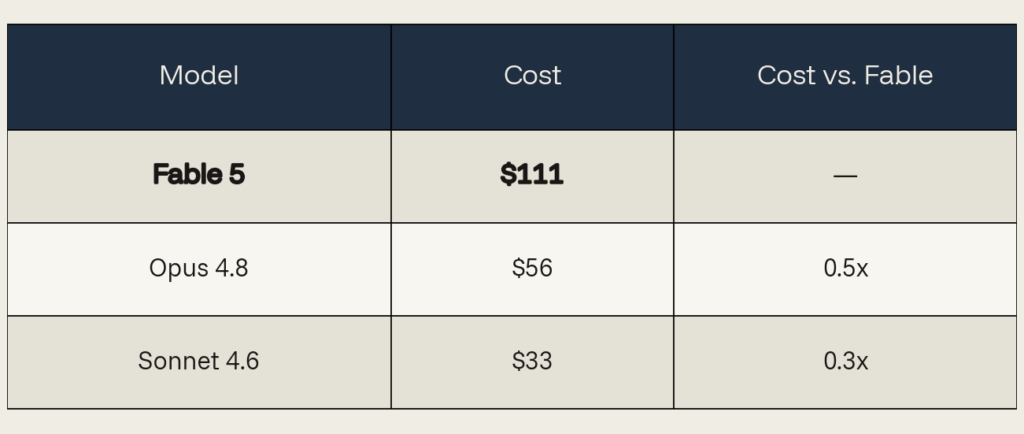
Same token usage, repriced.
Counterfactuals: We paid a premium for output that we could not meaningfully differentiate from that of cheaper models.
The verdict: premium wasted. The $55 premium over Opus went primarily toward context re-reads, not toward reasoning on the output. A smaller, well-prompted model with the right tool offload would have produced the same outcome for a fraction of the cost. The workload shape meant the premium multiplied churn rather than value.
The Bottom Line: When Fable 5 Can Help Maximize ROAI
Our experiments demonstrated that alignment between workloads and models is more important than workload size. The premium cost was earned on certain workloads, and not for others.
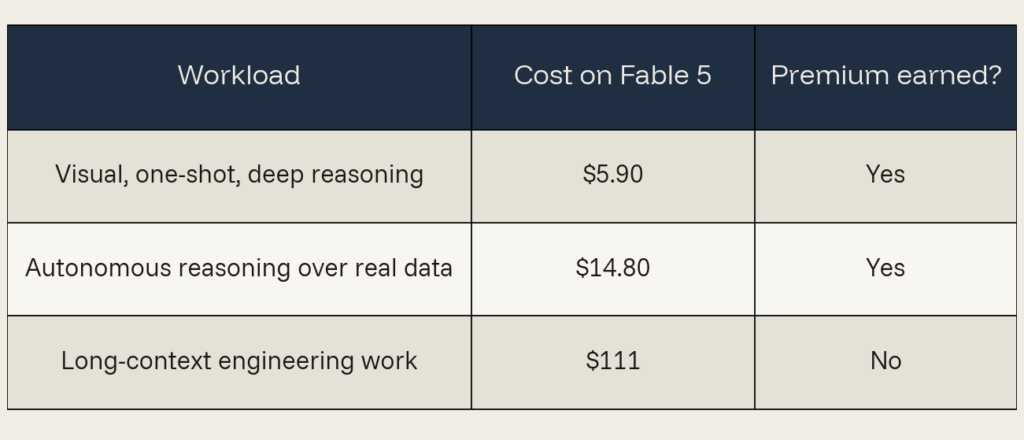
Engineering teams may reach for Fable 5 when:
- Reasoning quality decides the outcome. Choose Fable 5 when misunderstanding the prompt produces a wrong deliverable, not just a lower-quality one.
- The session is short and output-dominated. The deliverable is the cost; the premium applies to a small base.
- Correctness is difficult to verify independently. If Fable avoids one bad turn that a cheaper model would have taken, and that turn is expensive to discover later, the premium pays for itself.
Step down to Opus or Sonnet when:
- The session is a long, agentic build loop. Many turns over a large, growing context mean cost is dominated by cache reads.
- The work is mechanical. Cheaper model tiers lead to the same result on refactors, migrations, fan-out edits, document generation, or code reviews with known scope.
- Throughput matters more than peak quality. Parallel routine tasks or anything where “good enough, cheaply” beats “best, expensively.”
- Never use Fable for agents in the field. Fable 5 carries data handling and retention obligations that differ from the standard Anthropic tiers. Any autonomous agent with access to sensitive data, customer information, or internal systems must default to Opus or Sonnet, without exception.
Our experiments were illuminating, but most enterprises don’t have anyone running these kinds of evaluations. They pick a default model, point it at everything, and let the invoices pile up. When the bill lands, they throttle it. Both moves are wrong. What you actually need is a team that runs the math, workload by workload, every time a new model drops – and reshapes the workload itself when the cache tax shows up.
This is the work Optura does with healthcare organizations every day. Using our ROAI evaluation framework, we pressure-test workloads, match them to the right models, and pair them with the right tool offloads, prompt structures, and context strategies. Then we assess what work is actually earning a return, and where you can adjust to avoid losses.
Fable 5 is the latest premium model to drop, and it certainly won’t be the last. It’s time to get your AI evaluation frameworks in order, that way you’re ready for the next one.
Request a demo to see how Optura helps healthcare leaders measure ROAI and architect AI systems that pay back.



Stay up to date with thoughtful takes, real outcomes, and the moves leaders are making.
Subscribe Subscribe